Two Subtle Shifts in Model Capability That Changed Everything
If you've been building with large language models over the past two years, you've probably noticed that the discourse moves fast. Every few months there's a new framework, a new term, a new "paradigm." Agents, harnesses, context engineering, prompt caching, tool orchestration — the vocabulary keeps expanding.
But underneath all the noise, only two things actually changed. Two quiet capability shifts in how models are trained and evaluated. Everything else — the frameworks, the architectures, the product categories — is downstream of these two.
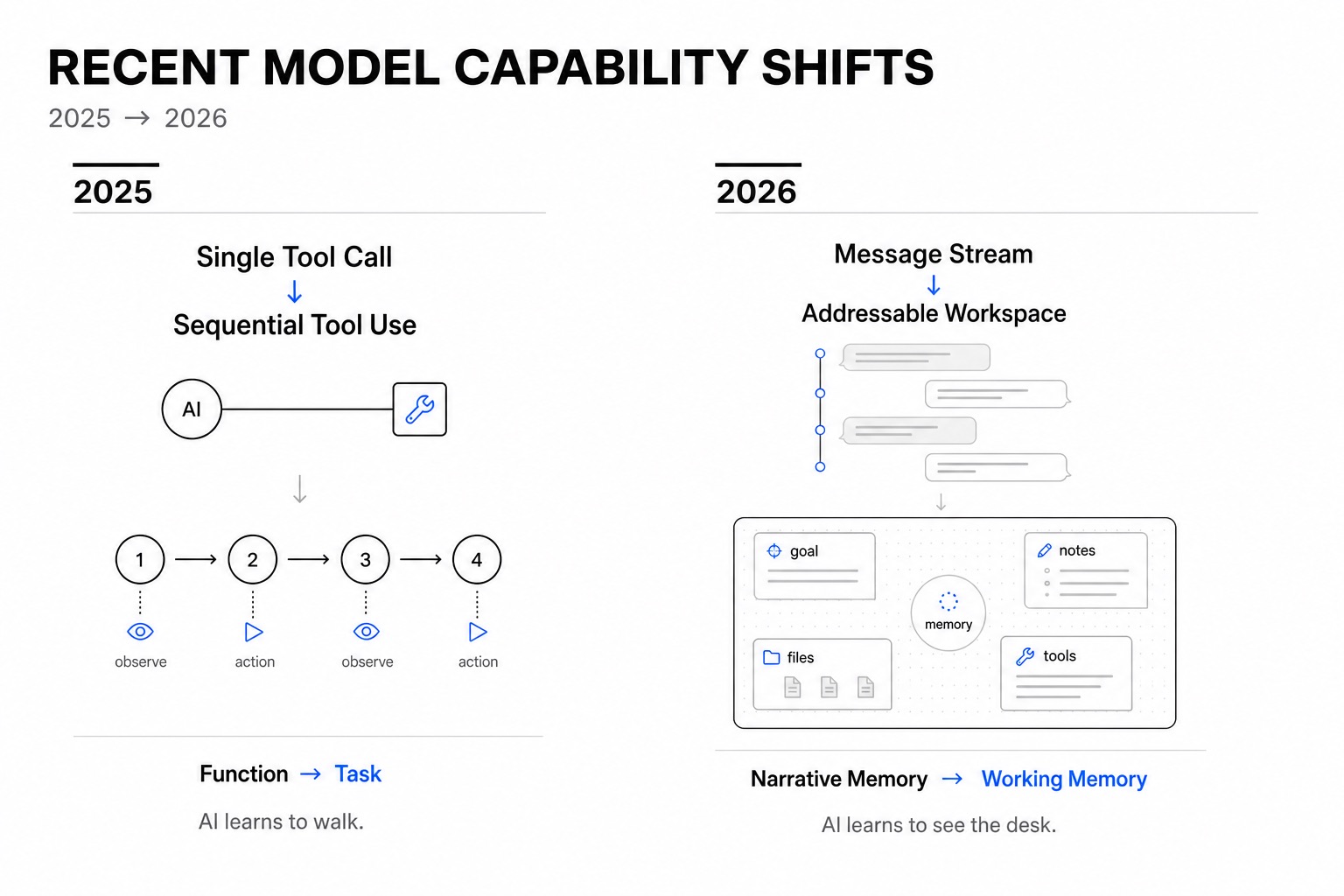
Shift 1: Single Tool Call → Sequential Tool Use (2025)
In early 2024, tool use looked like this:
One request, one tool call, one answer. The model was a router — it figured out which function to call, called it, and formatted the result.
By early 2025, something different was happening:
This looks like a small difference. It isn't.
The model is no longer routing — it's navigating. It holds a goal across multiple steps, interprets intermediate results, decides what to do next, and knows when to stop. Each observation reshapes the next action. The trajectory is not predetermined; it emerges from the interaction between the model's plan and the world's responses.
This is what turned tool use into agency. Not the ability to call tools — GPT-4 could do that in 2023. The ability to keep calling tools in a coherent direction without losing the plot.
The technical ingredients were not mysterious: better instruction following, longer reliable context windows, RLHF that rewarded multi-step task completion rather than single-turn helpfulness. But the result was a phase transition. Models went from completing functions to completing tasks.
If you want an analogy: the model learned to walk. Before, it could take one step. Now it could take many steps, in sequence, and end up somewhere useful.
Shift 2: Message Stream → Workspace (2026)
The second shift is harder to articulate, and it's still unfolding. But it's at least as important.
Since the dawn of chat-based LLMs, context has been organized as a message stream:
This is narrative context. It has a beginning, a middle, and an ongoing end. It's chronological. It's causal — each message responds to the one before it. To understand the state of the conversation, you essentially have to replay it. Like reading a novel, you can't skip to page 200 and know what's going on.
This worked fine for single-session chat. It even worked for the agentic tool-use pattern described above — a trajectory is still linear, still sequential.
But it breaks down the moment you want an AI that persists.
Consider what a persistent agent needs to know at any given moment:
- Who is the user (preferences, history, communication style)
- What is the current task (and how does it relate to previous tasks)
- What has been tried before (long-term memory)
- What tools and resources are available
- What files, documents, or data are relevant right now
- What is the agent's own role and operating instructions
You could encode all of this as a very long message history. People do. It's the "mega-prompt" approach — stuff everything into a linear context and hope the model can find what it needs.
But this is like storing a database as a single text file. It technically works. It doesn't scale. And more importantly, it forces the model to read when it should be able to look.
What's happening in 2026 is that context is becoming a workspace — a structured, addressable, non-linear space where different kinds of information coexist without requiring sequential narrative to connect them.
The model doesn't replay a story. It surveys a surface. It knows where things are, what's relevant to the current moment, and what can be ignored. The order in which information entered the workspace doesn't determine its importance — its relationship to the current task does.
This is the shift from narrative memory to working memory.
In cognitive science, narrative memory is episodic — it stores experiences as stories, ordered by time. Working memory is active and spatial — it holds whatever is relevant right now, organized by utility, not chronology.
When models were trained primarily on conversational data with message-stream structure, they developed strong narrative reasoning. They were good at following a thread, maintaining coherence across turns, and building on what came before.
The newer generation of models — trained with structured context, retrieval-augmented workflows, multi-source prompts, and persistent memory systems — are developing something different. They're learning to operate on a workspace. To treat context not as a story to follow, but as a desk to work at.
Why These Two Shifts Compound
Each shift is significant on its own. Together, they create something qualitatively new.
Sequential tool use gave us agents that can complete tasks. But those agents still lived and died within a single session. When the conversation ended, the agent was gone. When a new conversation started, it started from scratch.
Workspace context gives us agents that persist. An agent with a workspace doesn't need an ongoing conversation to exist — it needs a desk with its stuff on it. Close the laptop, open it tomorrow, everything is still there. The agent picks up where it left off, not by re-reading a transcript, but by looking at the current state of its workspace.
And here's where it gets interesting: a workspace can be shared. Multiple agents — or multiple roles of the same agent — can operate on the same workspace with different instructions. A planning agent writes a task breakdown; an execution agent picks it up. A research agent gathers information; a writing agent uses it. They don't need to "talk to each other" through messages. They work on the same surface.
This is also where the notion of persona changes. In the message-stream era, an agent had one persona: its system prompt. Everything that followed was that persona talking. In the workspace era, persona is no longer a fixed identity — it's a function of what's on the desk. Open the engineering workspace, and the agent thinks like an engineer. Open the writing workspace, and it thinks like a writer. Same model, different context, different behavior.
Not because someone "switched its personality," but because the workspace shaped what it attends to.
What This Means for Builders
If you're building AI applications today, the practical implications are:
Stop thinking in messages. Your context is not a chat log. It's a workspace. Design it like one — with named regions, structured data, and clear spatial organization. The model will use it better than a 50,000-token narrative dump.
Invest in context architecture. The term "context engineering" exists for a reason. How you assemble, structure, and manage what goes into the model's context window is now a first-class engineering problem — arguably the engineering problem of AI application development.
Design for persistence. If your agent can only operate within a single session, you're leaving the biggest capability gain of 2026 on the table. Give your agent a workspace that survives across sessions. Let it wake up and see its desk.
Think in trajectories, not calls. When you design tool integrations, don't optimize for single-call accuracy. Optimize for multi-step reliability. The model will call your tools in sequences you didn't anticipate. Make sure each tool returns enough information for the model to decide what to do next.
The discourse will keep generating new terms. By the time you read this, there will probably be three more frameworks and a dozen new acronyms. But the underlying capability shifts are simple:
In 2025, models learned to take many steps. In 2026, they learned to see the whole desk.
Everything else follows.