How to Design Prompt Cache for Long-Context Agents: A Real Atypica.AI Experiment
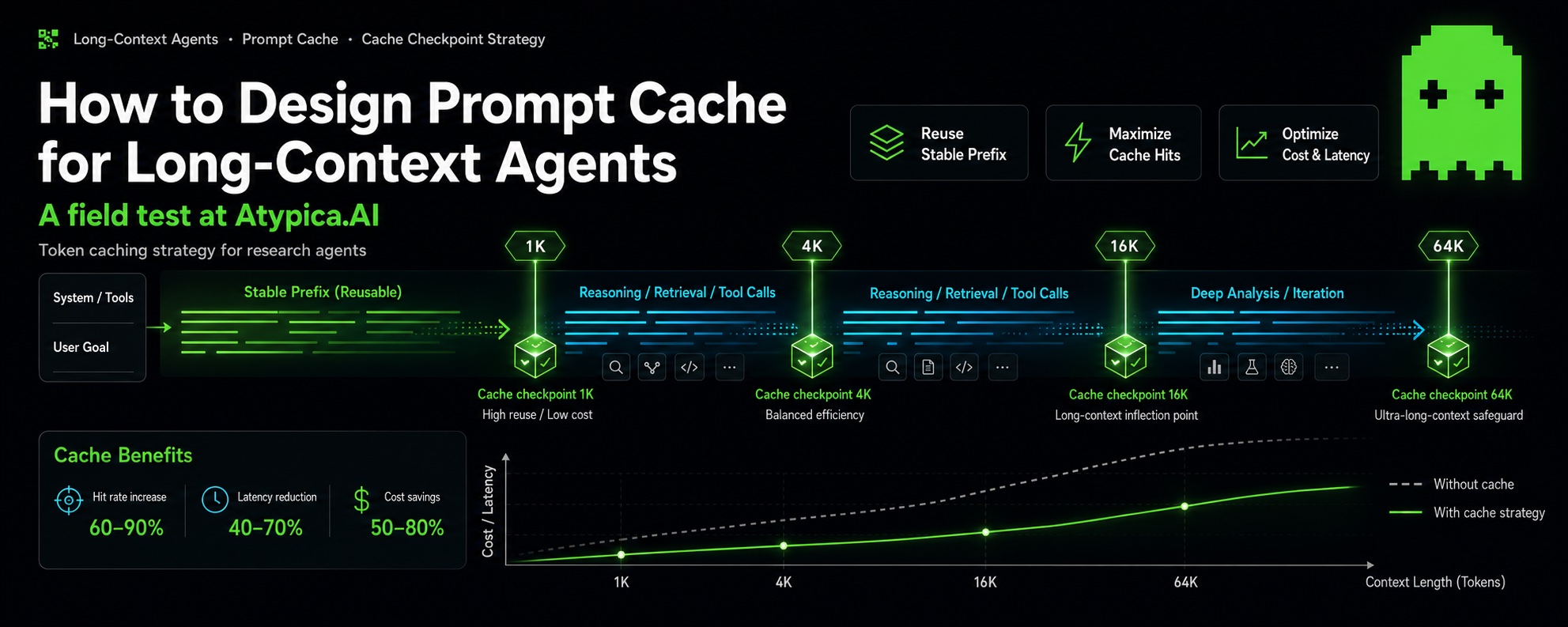
Why Cache?
If an AI agent only answers one or two rounds of questions, token cost is usually easy to understand: how much the user sends in, how much the model returns, and the bill roughly follows. Research agents are different.
In the commercial research-agent scenario at Atypica.AI, a task continuously accumulates user requirements, research plans, tool search results, interview notes, sub-agent conclusions, and interim reports. The further the task progresses, the more each model call needs to carry the long context already built up earlier.
Before optimization, one of our reports usually consumed around 600,000 tokens.
The real source of runaway cost is not "how many tokens were generated this time," but rather:
The same stable long prefix is repeatedly sent back into the model.
Claude Prompt Cache is designed to solve exactly this problem: cache the stable, sufficiently long prompt prefix that will appear repeatedly later. When subsequent requests hit the same prefix, they no longer need to be billed as full input again.
An easily overlooked point is that Anthropic/Claude Prompt Cache does not "automatically cache conversation history." Engineering-wise, cache control must be manually added to request messages. Place it too early, and the cached prefix is too short to be valuable. Place it too often, and cache writes themselves increase cost.
For Claude requests, code needs to write provider options onto messages, such as anthropic.cacheControl or Bedrock's cachePoint. Without this step, there is no controllable checkpoint. See https://platform.claude.com/docs/en/build-with-claude/prompt-caching

Checkpoints should follow token length, not message count. One tool output can be longer than a dozen chat messages. Message count is not a reliable proxy. We recommend placing checkpoints only on stable message boundaries. Online requests cannot be split at arbitrary token positions. Cache options can only be attached to reproducible message boundaries such as system, user, and assistant messages.
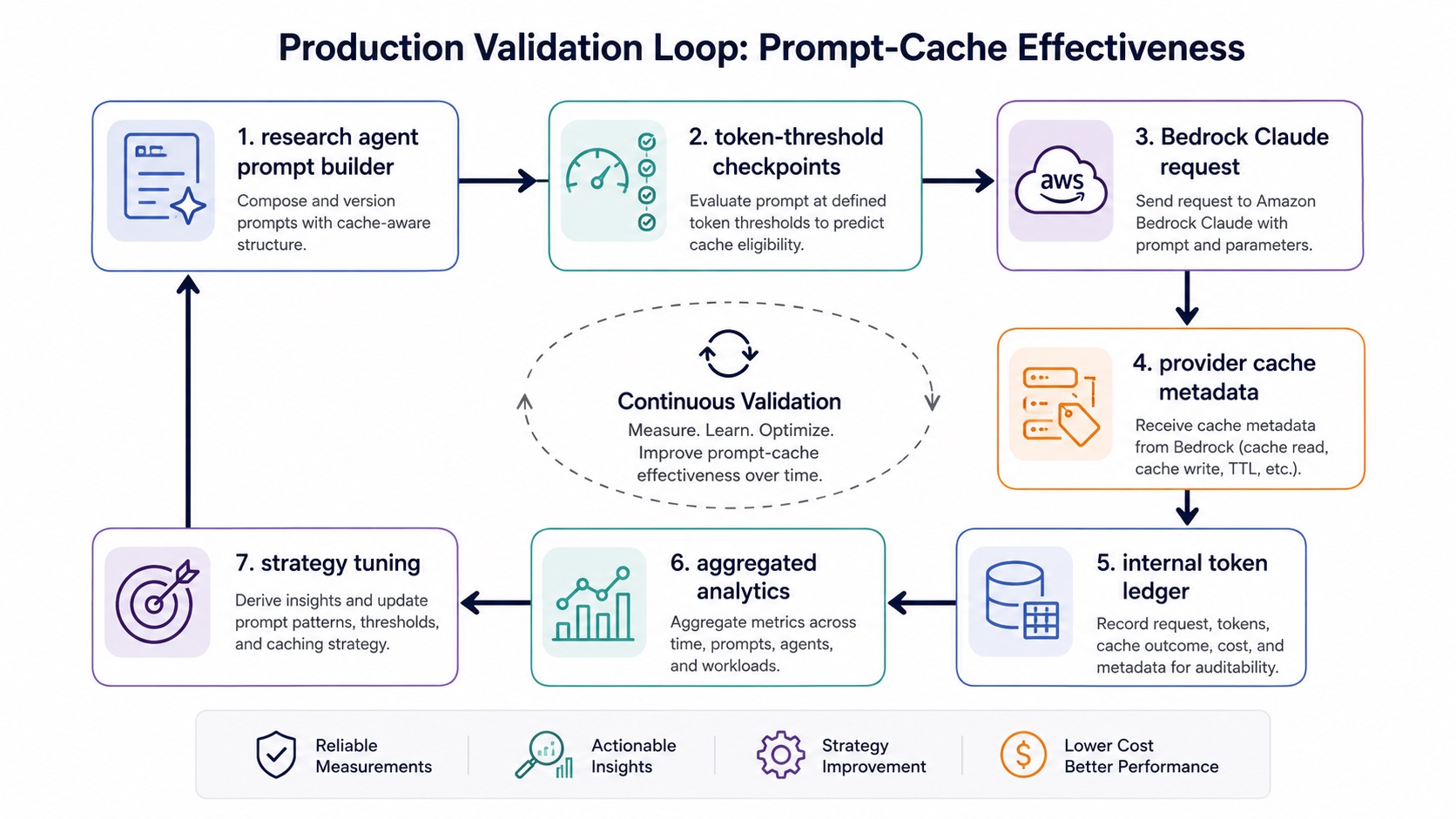
Our conclusion is: do not place checkpoints by "message number." Place them by cumulative input token length. The strategy should first be simulated offline using historical sessions, then verified online with cache metadata. Use real ChatMessage and ChatStatistics records from the DB for offline simulation, then use provider metadata for online verification. Without real cache read/write statistics, cache optimization easily remains stuck at "it should save money in theory." Offline verification also lets us estimate token consumption without repeatedly running the dynamic workflow online, making it much easier to experiment and reach a practical conclusion.
Research Process: Static Offline Analysis on 20 Production Sessions
A caching strategy should not go online just because it "looks reasonable." We needed to answer a more specific question:
If this checkpoint strategy is applied to real historical Study tasks, can it actually read long prefixes that are reused later?
To answer this, we built an offline simulator. This process mattered more than the final thresholds themselves, because it turned caching strategy from "experience-based judgment" into "a reproducible cost experiment."
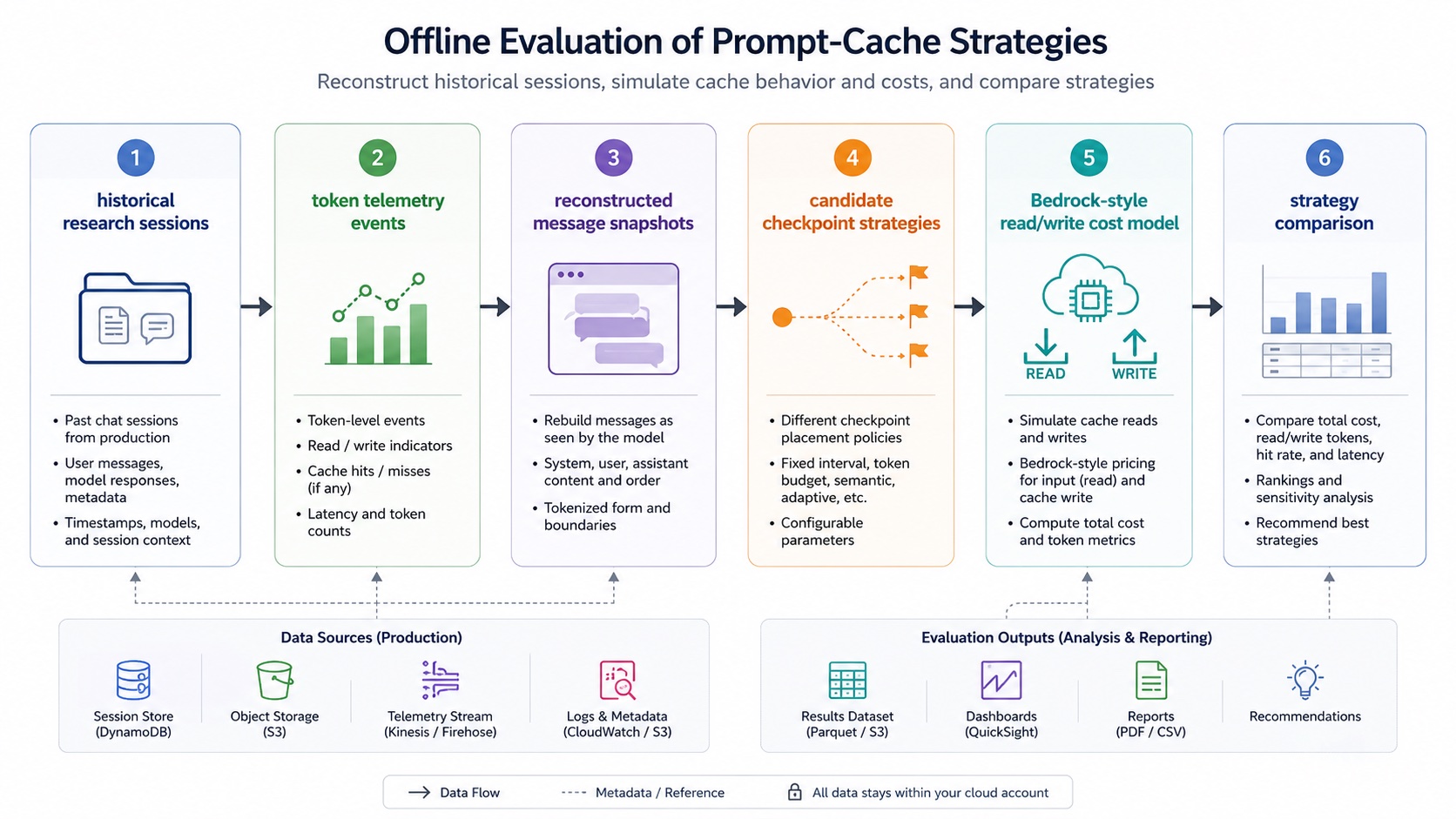
The simulator's key inputs were not summaries returned by an API, but two kinds of real records from the database:
ChatMessage: reconstructs which historical messages the agent could see before each model call;ChatStatistics: provides real token-statistics events and the times when those events occurred. The overall process was:
- Select 20 representative high-token-consumption
UserChat.kind = 'study'tasks from production data; - Treat each
ChatStatistics(tokens)row as one real token event; - Reconstruct the prompt prefix at that time from
ChatMessagebased on the event timestamp; - Simulate different checkpoint strategies on that prefix;
- Estimate billed input using a Bedrock-style cache read/write cost model;
- Compare cache read rate and estimated savings across strategies. The strategies we tested included:
| Strategy | Example | Purpose |
|---|---|---|
| Current index strategy | current-message-index | Baseline for the first implementation |
| Fixed token thresholds | 1K / 4K / 16K / 64K, 4K / 12K / 24K / 48K, etc. | Test whether cumulative-length checkpoints save more |
| Long-prefix quantiles | 25% / 50% / 75% / 90% | See whether "relative position" beats fixed thresholds |
| Recent assistant boundaries | last-4-assistant-boundaries | Test whether boundaries close to the current call are easier to hit |
| Tool phase boundaries | planning, interview, discussion, sub-agent, report | Test whether semantic phases can serve as cache boundaries |
There is an easy trap here: token rows and message rows cannot be directly joined and summed. That would inflate token statistics. The correct approach is to aggregate token events and messages separately, then align them by time inside the simulation layer. We also ran a conservative run: exclude statistics events that were clearly not chat-history reuse scenarios, such as web search, report cover image, generateReport, and image generation; and drop the assistant output that had just been generated, approximating the input snapshot "before sending to the model." This lowers absolute savings, but better reflects the real request prefix.
Cache Cost Model: Cache Writes Are Not Free
Prompt Cache's benefit comes from reads, but its cost comes from writes. If a checkpoint is written and almost no later requests read it, that write is extra cost. So we compared strategies with a model approximating Bedrock Claude's cache billing shape:
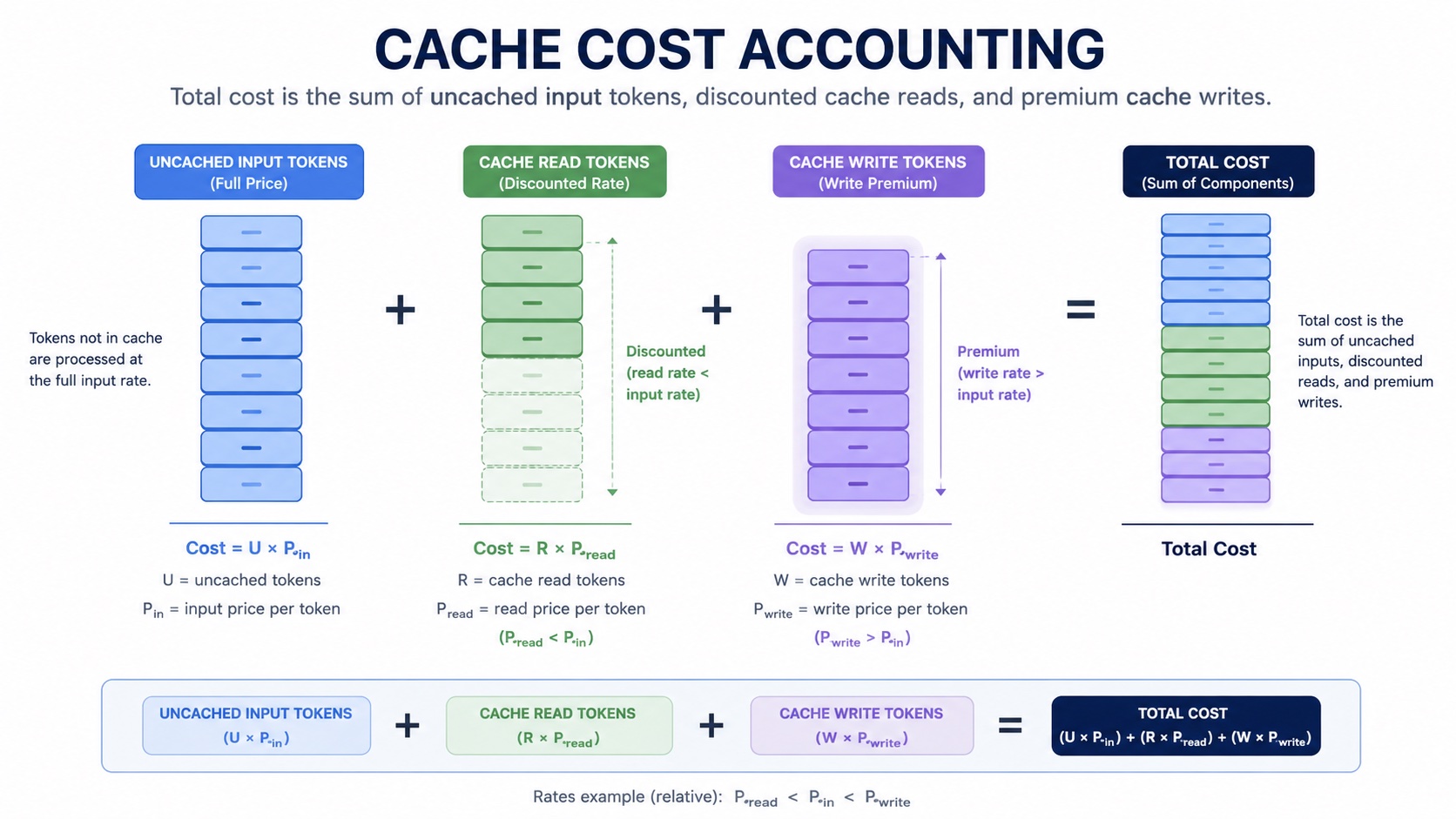
This model intentionally does two things at the same time:
- Rewards long-prefix reuse: the more cache reads, the lower the estimated cost;
- Penalizes ineffective writes: frequent cache writes that are not read later are pushed up by the write premium. In other words, we were not comparing "which strategy places more checkpoints," but "which strategy can turn checkpoints into cache that is actually readable later."
How Did We Know Where to Place Cache Checkpoints?
After multiple rounds of experiments, the final production implementation uses:
const thresholds = [1024, 4096, 16384, 65536];
That is 1K / 4K / 16K / 64K. This was not chosen by intuition. It converged through one full round of research:
- The first version placed checkpoints by message index;
- We found that the index strategy was inefficient in long-context Study sessions;
- We pulled 20 representative high-token-consumption sessions from production;
- We reconstructed the prompt prefix before each call using real
ChatMessagerecords; - We used
ChatStatisticstoken events as time anchors; - We ran multiple checkpoint strategies and compared the final estimated token consumption;
- We then verified real cache writes and reads through the Anthropic path.
In the offline results,
4K / 12K / 24K / 48Kscored highest in the base run. But conservative simulation and production explainability favored1K / 4K / 16K / 64Kas the default strategy. This distinction matters: we were not chasing the single highest score in one offline table, but choosing a more robust default across savings, stability, and engineering observability.
Version 1: Cache by Message Index
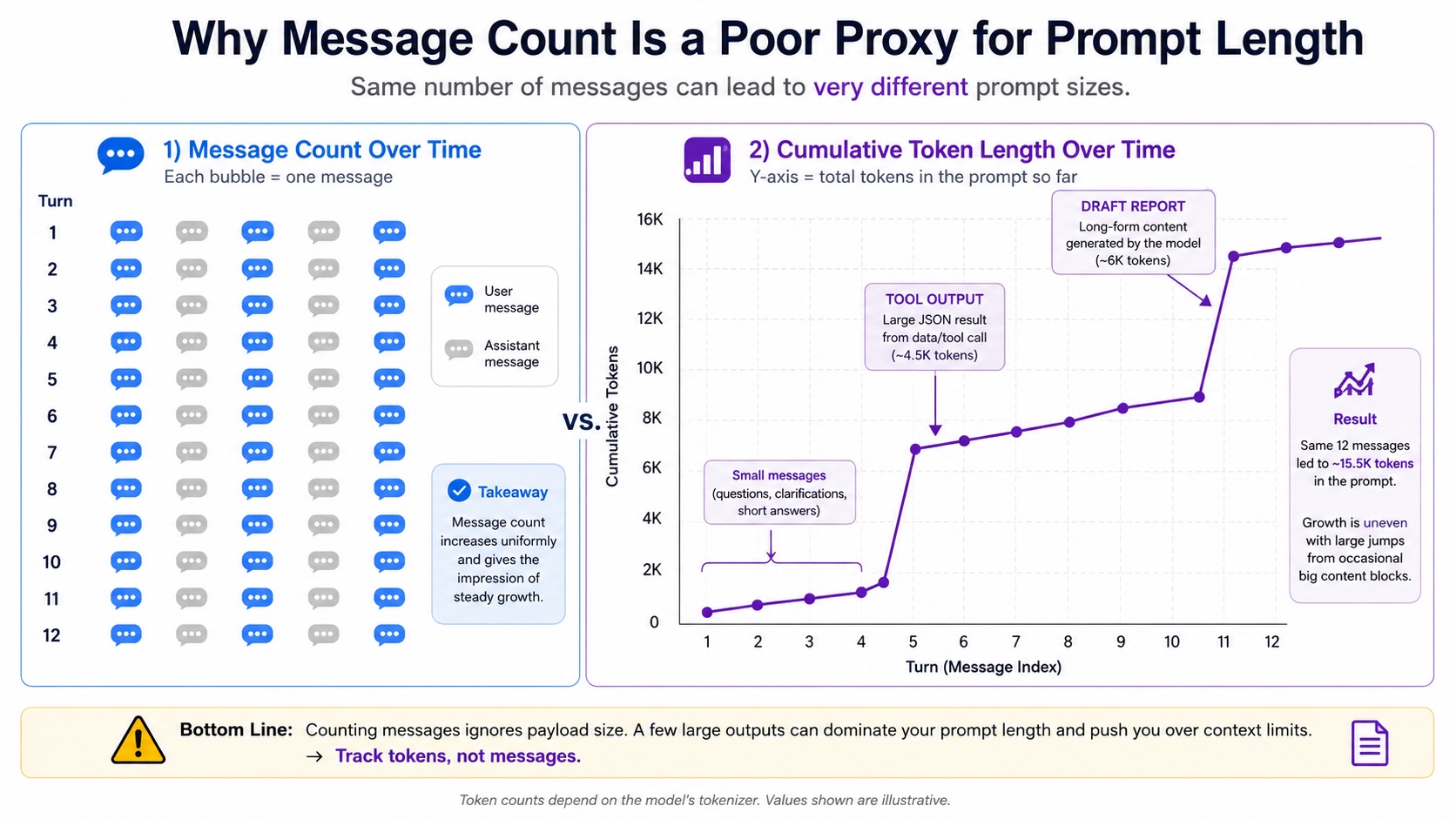
At first, we used the easiest strategy to think of: a message-index heuristic.
The problem with this strategy is that it assumes "message count" roughly correlates with "context length." In research agents, this assumption often fails:
- The first 20 messages may only be short plans and status updates, totaling less than a few thousand tokens;
- Message 21 may be a tool result that directly adds tens of thousands of tokens;
- Message 22 may be a report draft that adds tens of thousands more. After running it in practice, we found that this assumption did not hold in Study. If a checkpoint is placed too early, it only caches a short prefix and provides little value on later reads. If a checkpoint is placed too late, it misses many intermediate contexts that have already stabilized and are being reused. If one tool message suddenly becomes very long, placing checkpoints by index can completely miss the context inflection point where cost is highest. So we switched to a token-length heuristic:
Do not care which message number we are on. Care only whether cumulative input tokens have crossed key thresholds.
Version 2: Place Checkpoints by Cumulative Token Thresholds
The strategy itself is not complicated.
- Iterate through the messages about to be sent to the model in order;
- Estimate the token length after each message is serialized;
- Accumulate the current prompt's input tokens;
- When cumulative tokens cross a threshold, place a checkpoint at a nearby cacheable message boundary;
- Keep at most 4 checkpoints, matching Claude Prompt Cache constraints;
- Choose only stable, reproducible message boundaries for production.
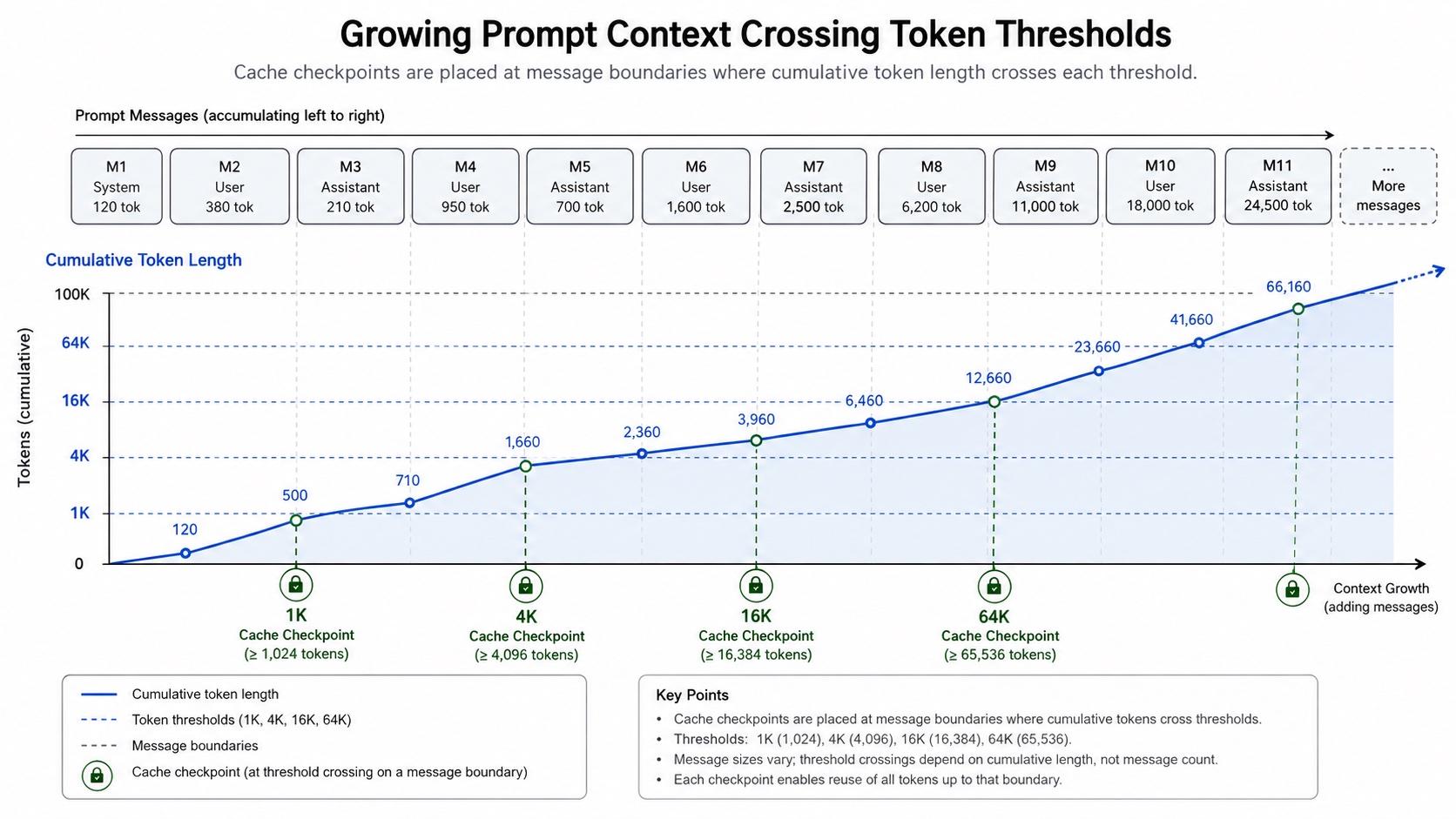
The current production implementation uses 1K / 4K / 16K / 64K:
const thresholds = [1024, 4096, 16384, 65536];
The meaning of these thresholds is straightforward:
- 1K: Let shorter research tasks reuse stable prefixes as early as possible;
- 4K / 16K: Cover the range where most Study tasks enter dense tool results and interim summaries;
- 64K: Keep a later checkpoint for very long research tasks, preventing all cache points from clustering early;
- At most 4 points: Align with provider limits and keep engineering behavior more controllable. This strategy does not try to understand the semantics of every tool output, nor does it need to predict the final context length. It focuses on one thing: once the input prefix is long enough to be worth reusing, leave a cache point on a stable boundary.
Simulation Results: The Index Strategy Was Basically Insufficient
The first base run used 20 high-token Study sessions:
- Actual internal token ledger total: 11.3M;
- Token statistics events: 1,779;
- Message-derived simulated calls: 1,779;
- Message-derived estimated input tokens: 53.3M.
In this round,
4K / 12K / 24K / 48Kwas the strongest static candidate:
| Strategy | Read rate | Est. savings | Cache read | Cache write | Est. billed input |
|---|---|---|---|---|---|
token-thresholds-4k-12k-24k-48k | 98.6% | 86.9% | 52.6M | 747.0K | 7.0M |
long-prefix-quartiles | 98.6% | 86.8% | 52.6M | 851.0K | 7.1M |
last-4-assistant-boundaries | 98.7% | 86.6% | 52.7M | 974.6K | 7.2M |
tool-phase-boundaries | 83.4% | 73.6% | 44.5M | 610.0K | 14.1M |
current-message-index | 3.2% | 2.6% | 1.7M | 121.0K | 52.0M |
This result shows that the first index-based strategy was not merely slightly behind. It basically failed to capture the truly long prefixes that Study actually reuses. But the base run was still optimistic, because when some token stats were recorded, the assistant output may already have been written into the database. So we ran the conservative run: excluding non-chat-history reuse events and dropping the current assistant output.
| Strategy | Read rate | Est. savings | Cache read | Cache write | Est. billed input |
|---|---|---|---|---|---|
token-thresholds-1k-4k-16k-64k | 87.1% | 72.9% | 4.8M | 240.4K | 1.5M |
token-thresholds-1k-2k-4k-8k | 87.1% | 72.9% | 4.8M | 240.4K | 1.5M |
long-prefix-quartiles | 86.9% | 72.8% | 4.8M | 240.4K | 1.5M |
token-thresholds-4k-12k-24k-48k | 58.8% | 48.5% | 3.2M | 218.6K | 2.9M |
current-message-index | 0.4% | 0.0% | 21.7K | 21.7K | 5.5M |
This is why we ultimately chose 1K / 4K / 16K / 64K: 4K / 12K / 24K / 48K was highest in the base run, but 1K / 4K / 16K / 64K was more robust in the conservative run, and it is easier to explain and monitor. A production default should prioritize robustness and observability, not only the highest score in one offline sample.
The most important point is not to treat 72.9% or 86.9% as a promise of online savings, but to understand the strategy difference:
Message-index checkpoints often fail to cache the prefixes that are truly long and truly reused; token-threshold checkpoints are more likely to hit the cost concentration zones of research agents.
This matches the context structure of the Study scenario. Cost is not evenly distributed across messages. It concentrates after a small number of long tool outputs, subtask summaries, and report drafts.
Real Provider Metadata Still Needs to Be Verified Before Launch
Offline simulation can only show that "this strategy is more reasonable on historical context." It cannot prove that real requests will hit cache. Before launch, two additional things need to be verified:
- Whether the cache option is actually included in Claude requests;
- Whether the cache metadata returned by the provider can be recorded in the internal token ledger.
We ultimately need to see these fields in the statistics pipeline:
cacheReadInputTokens, cacheWriteInputTokens
This step is critical. In engineering work, three states often look similar but are actually completely different:
- The code selected a checkpoint;
- The request actually carried the cache option;
- The provider actually returned cache read/write data.
Only when the third state enters
ChatStatistics.extra.cachecan we say that cache savings have entered the observable ledger. In a smoke test through the PPIO/Anthropic path, when the same long prefix was requested consecutively, the first request returned:
The second request returned:
This shows that both cache write and cache read can be obtained from provider metadata. Later, in the local Study verification path, we also saw cacheReadInputTokens and cacheWriteInputTokens land in the statistics table, proving that this pipeline not only works at the request layer but also enters Atypica.AI's own token ledger.
Engineering Lessons From This Optimization
First, caching strategy should be designed around prefix reuse. For long-context agents, the main cost is often repeated input of stable prefixes, not one-off output.
Second, Anthropic caching requires manual checkpoints. Do not understand Prompt Cache as provider-side automatic optimization. The system must explicitly choose boundaries and write cacheControl / cachePoint / cache_control into requests.
Third, cache writes have a cost. Writing more does not necessarily save more. The write premium can only be amortized when later requests truly read a sufficiently long stable prefix.
Fourth, message count is not a reliable metric. Tool calls, report drafts, and sub-agent results can all make the context suddenly much longer. The message number does not tell you whether the prefix is worth caching.
Fifth, fixed token thresholds are a strong default. They are simple enough, easy to explain, easy to monitor, and do not depend on complex semantic judgments about workflow stages.
Sixth, offline simulation must use real messages and real token events. Looking only at API summaries or current frontend statistics can easily understate or overstate historical calls.
Seventh, online verification must land in the cache read/write ledger. Without provider metadata, it is hard for a cache strategy to move from "theoretical optimization" to "sustainable optimization."
Conclusion
For research agents, Prompt Cache is not a simple switch. It is a cost strategy designed around how long context grows. The core lesson from this Atypica.AI experiment can be summarized in one sentence:
Manually place checkpoints on stable message boundaries after cumulative tokens cross key thresholds, then verify the strategy with real historical data and online cache metadata.
This method does not try to find a permanently optimal set of thresholds in one shot. Its more important value is establishing an iterative loop: choose a strategy from historical tasks, verify savings with real provider metadata, then continue calibrating thresholds with new online data. In the end, cost optimization for long-context agents is not about one magic parameter. It is about connecting context structure, provider billing models, and internal statistics ledgers into one reliable chain.